服务热线:13988889999
站内公告:
2024-03-12 11:57:10 点击量:
Adam
梯度下降法参数更新公式:
θt+1=θt?ηJ(θt)
其中,η是学习率,θt 是第 t 轮的参数,J(θt) 是损失函数,?J(θt)是梯度。
在最简单的梯度下降法中,学习率 η是常数,是一个需要实现设定好的超参数,在每轮参数更新中都不变,在一轮更新中各个参数的学习率也都一样。
为了表示简便,令 gt=?J(θt),所以梯度下降法可以表示为:
θt+1=θt?η?gt
Adam,是梯度下降法的变种,用来更新神经网络的权重。
Adam 更新公式:


默认值为 η=0.001,β1=0.9,β2=0.999,?=1e?8。其中,β1 和 β2 都是接近 1 的数,? 是为了防止除以 0。gt 表示梯度。
前两行是对梯度和梯度的平方进行滑动平均,即使得每次的更新都和历史值相关。
中间两行是对初期滑动平均偏差较大的一个修正,叫做 bias correction,当 t 越来越大时,1?βt1 和 1?βt2 都趋近于 1,这时 bias correction 的任务也就完成了。
最后一行是参数更新公式。
学习率为 η/√v^t+?,每轮的学习率不再保持不变,在一轮中,这是因为 η 除以了每个参数 1/1?β2=1000 轮梯度均方和的平方根。而每个参数的梯度都是不同的,所以每个参数的学习率即使在同一轮也就不一样了。而参数更新的方向也不只是当前轮的梯度 gt了,而是当前轮和过去共 1/1?β1=10 轮梯度的平均。
对 Adam 这些自适应学习率的方法,还应不应该进行 learning rate decay?
这些学习率衰减都是直接在原学习率上乘以一个 factor
每30个epoch学习率按照10%衰减的代码实现:
param_group中保存了参数组以及对应的学习率、动量等,可以通过更改param_group[‘lr’]的值来更改对应参数组的学习率。
SGD
随机梯度下降算法每次从训练集中随机选择一个样本来进行学习。
批量梯度下降算法每次都会使用全部训练样本,因此这些计算是冗余的,因为每次都使用完全相同的样本集。而随机梯度下降算法每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。
随机梯度下降最大的缺点在于每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动)。
不过从另一个方面来看,随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。
由于波动,因此会使得迭代次数(学习次数)增多,即收敛速度变慢。不过最终其会和全量梯度下降算法一样,具有相同的收敛性,即凸函数收敛于全局极值点,非凸损失函数收敛于局部极值点。
交叉熵损失
设某一事件发生的概率为P(x),其信息量表示为:
I(x)=?log(P(x))
其中I(x)表示信息量,这里log表示以e为底的自然对数。
信息熵
信息熵也被称为熵,用来表示所有信息量的期望。
期望是试验中每次可能结果的概率乘以其结果的总和。
所以信息量的熵可表示为:(这里的X是一个离散型随机变量)
H(X)=-∑?P(xi?)log(P(xi?)))(X=x1?,x2?,x3?…,xn?)
相对熵(KL散度)
如果对于同一个随机变量X有两个单独的概率分布P(x)和Q(x),则我们可以使用KL散度来衡量这两个概率分布之间的差异。
下面直接列出公式,再举例子加以说明。
DK|L?(p∣∣q)=∑p(xi?)log(p(xi?)?/q(xi?))
在机器学习中,常常使用P(x)来表示样本的真实分布,Q(x)来表示模型所预测的分布,KL散度越小,表示P(x)与Q(x)的分布更加接近,可以通过反复训练Q(x)来使Q(x)的分布逼近P(x)。
交叉熵公式表示为:
H(p,q)=∑?p(xi?)log(q(xi?))
在机器学习训练网络时,输入数据与标签常常已经确定,那么真实概率分布P(x)也就确定下来了,所以信息熵在这里就是一个常量。由于KL散度的值表示真实概率分布P(x)与预测概率分布Q(x)之间的差异,值越小表示预测的结果越好,所以需要最小化KL散度,而交叉熵等于KL散度加上一个常量(信息熵),且公式相比KL散度更加容易计算,所以在机器学习中常常使用交叉熵损失函数来计算loss就行了。
交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。
交叉熵在分类问题中常常与softmax是标配,softmax将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。
SNR
该方法指的是我们将我们的模型输出结果与真实标签作为区分,用真实值减去生成值的评分作为分母,真实值的平方作为分子再取对数,所得到的最终结果越大越好。这样做看上去可行但是,他会有一个问题就是当我们真实值与生成值所处方向是平行的(意味着只是声音响度的大小不同),效果已经很好了,但是他的误差还是会很大,在一个当我们的真实值与生成值的方向不一样的,模型学到的有可能是将真实的声音放大,因为这样可以产生更小的误差(如下图所示),显然这样是不合理的。
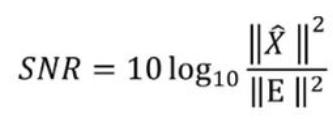
SI-SNR&SI-SDR
也是文献中常用的评估方法,他将生成向量投影到真实向量的垂直方向,我们叫他为 Xe ,在把该向量作为分母,我们可以得出在两向量平行的时候评估结果是无限大的,而且向量方向偏差越大, Xe的值就越大,完全符合预期。

SI-SNR improvement
该方法作为SI-SNR的升级版,我们用混合的声音与真实的声音做一次SI-SDR,用生成的声音与真实的声音做一次SI-SDR,再将上述两种值进行相减,这样做的好处就是我们可以只看变化部分的多少,而不是说混合声音本身就是很接近真实声音了,所以SI-SDR也会很大。
Permutation Invariant Training
该方法解决了标签排放的问题,他是将声音的两种标签都同时进行训练,然后找出loss最小的那一个标签.

Copyright © 2012-2018 首页-杏悦-杏悦注册站 版权所有
地址:海南省海口市玉沙路58号电话:0898-88889999手机:13988889999
ICP备案编号:琼ICP备88889999号

微信扫一扫







